- Attention
- 어느 시점 정보가 RNN의 최종 출력 값에 영향을 미치는지를 알려줄 수 있는 메커니즘

① 각각의 hidden state가 어느 정도의 중요도를 갖는지(=attention score) 산출하는 NN
② α = attention score
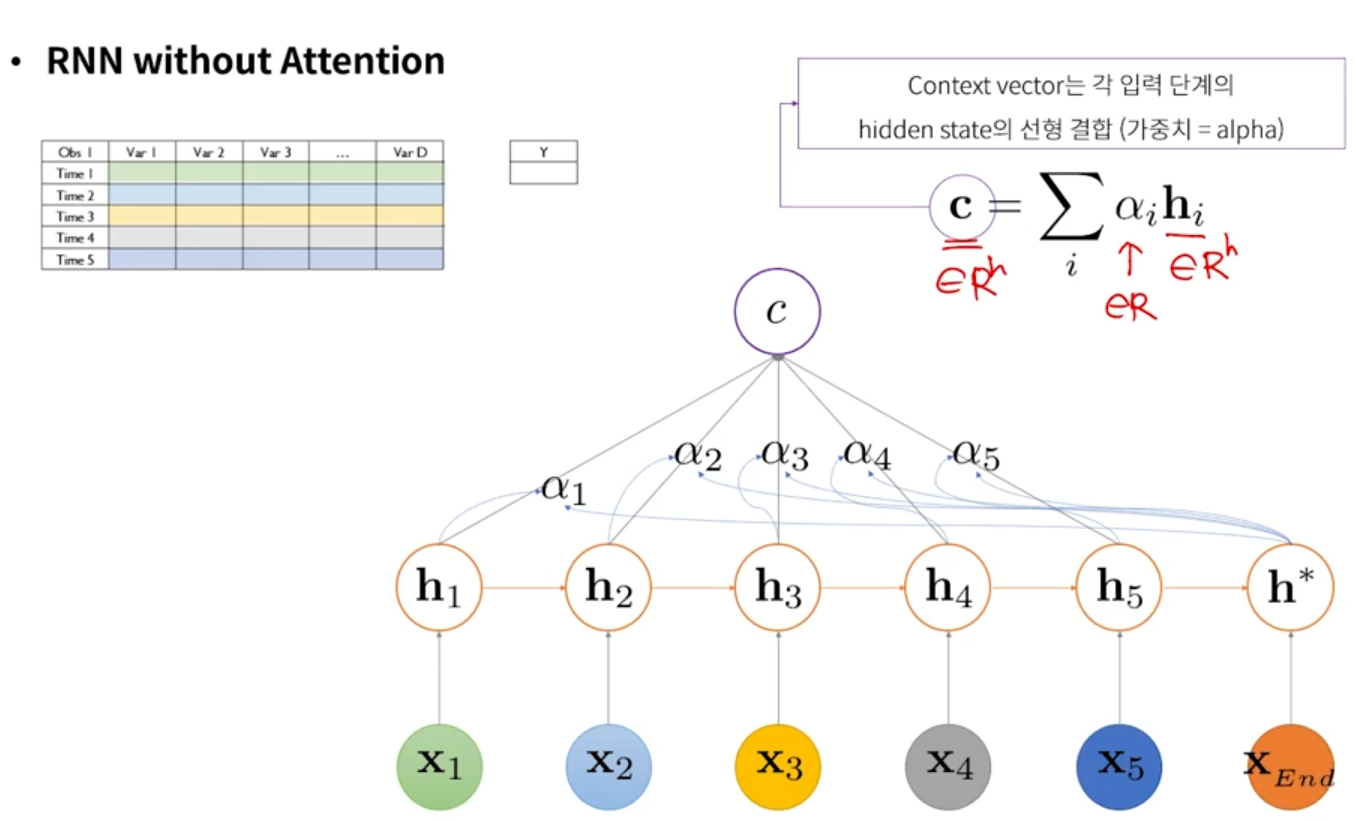
③ 기존 hidden state를 그대로 가져오는게 아니라, 현재 시점의 output을 만드는데 중요하게 역할을 하는 시점이 어느 시점인지를 scalar 값으로 산출하고, 이렇게 산출된 scalar 값(α)과 hidden state 들을 선형 결합해서 하나의 vector로 표현함 → context vector
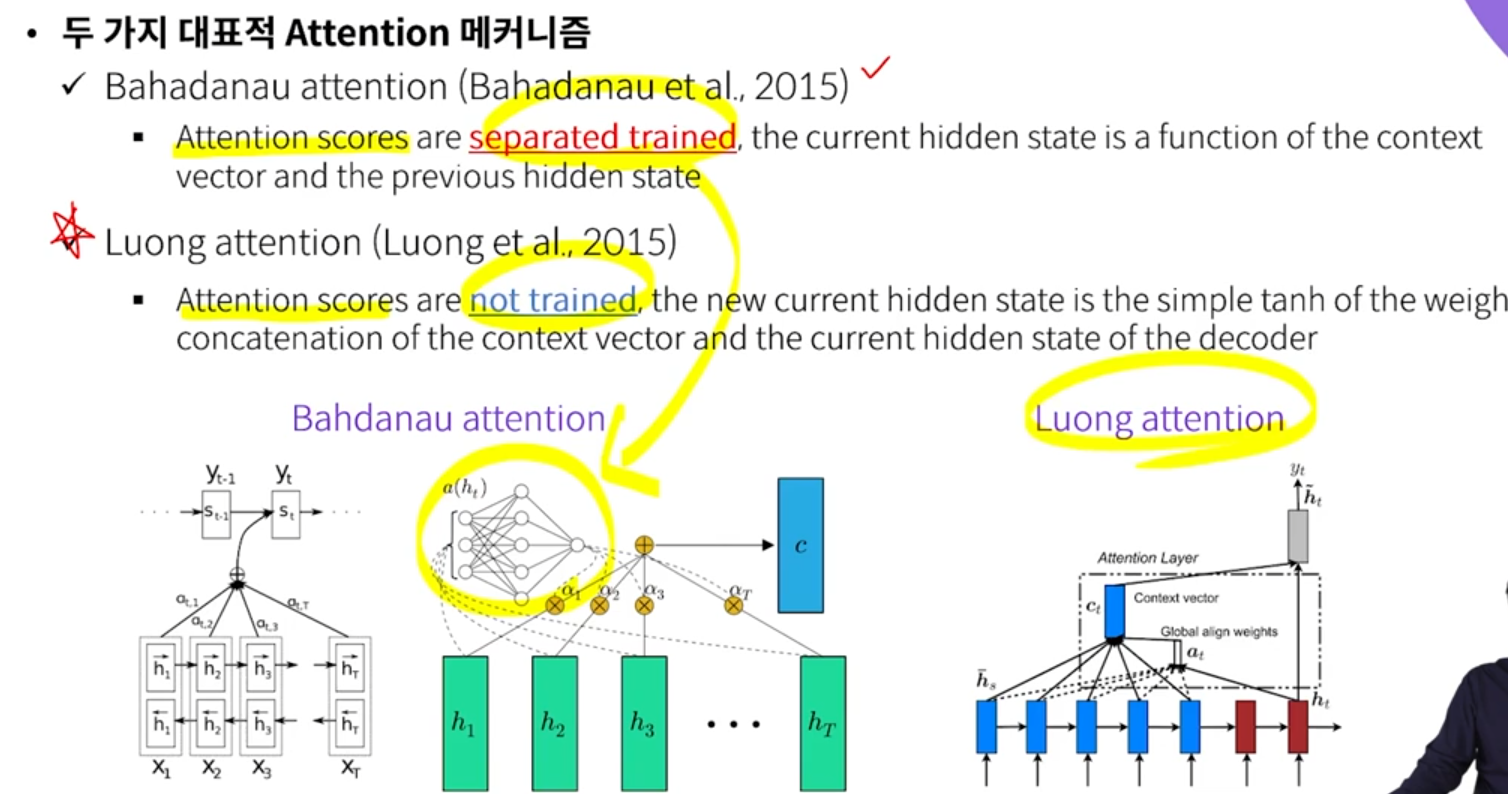
- Luong attention은 attention score를 따로 학습하지는 않지만, Bahdanau attention 의 성능과 크게 차이가 나지 않기 때문에, Luong attention을 조금 더 효율적으로 사용할 수 있다.
- Vanilla RNN (LSTM, GRU)

- Luong attention
- Attention 이 있으면 context vector를 만들어낸다.
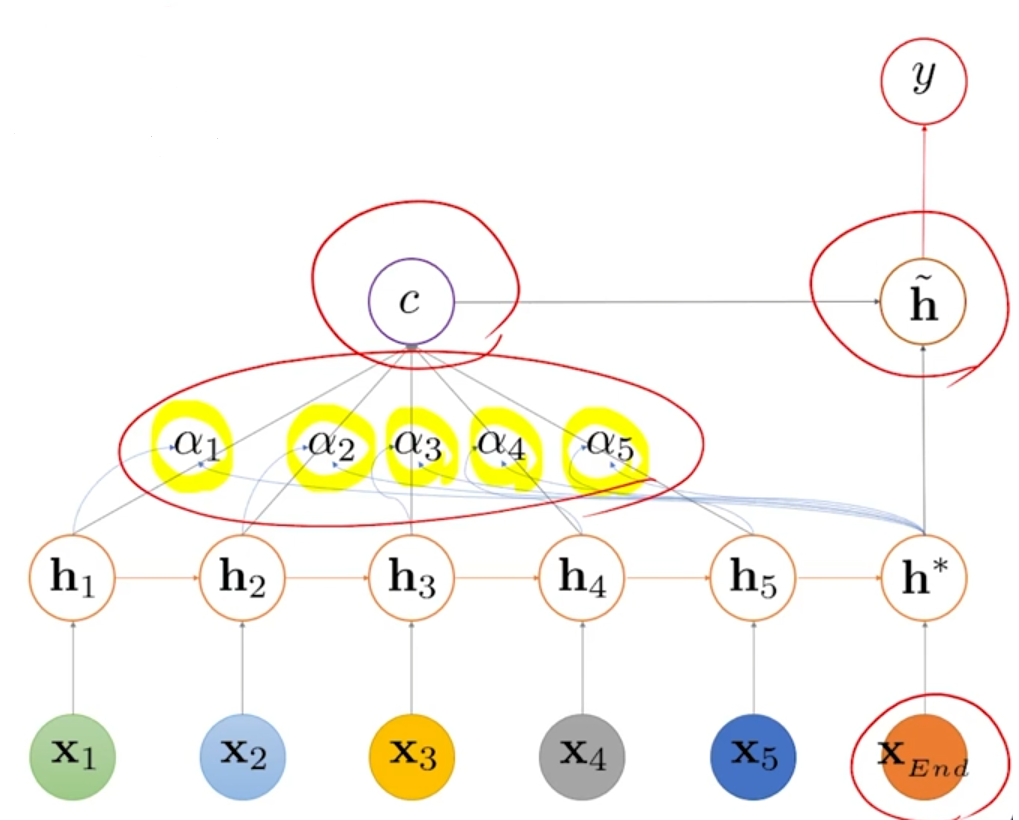
1. Attention score (α)
- score(h*, hi) 의 계산을, Bahdanau attention에서는 학습하지만, Luong attention 에서는 logic으로 계산한다.
- 가장 간단한 logic은 벡터의 내적. 벡터의 내적이 높다는 것은 두 벡터의 유사성이 높다는 것.

2. Context vector
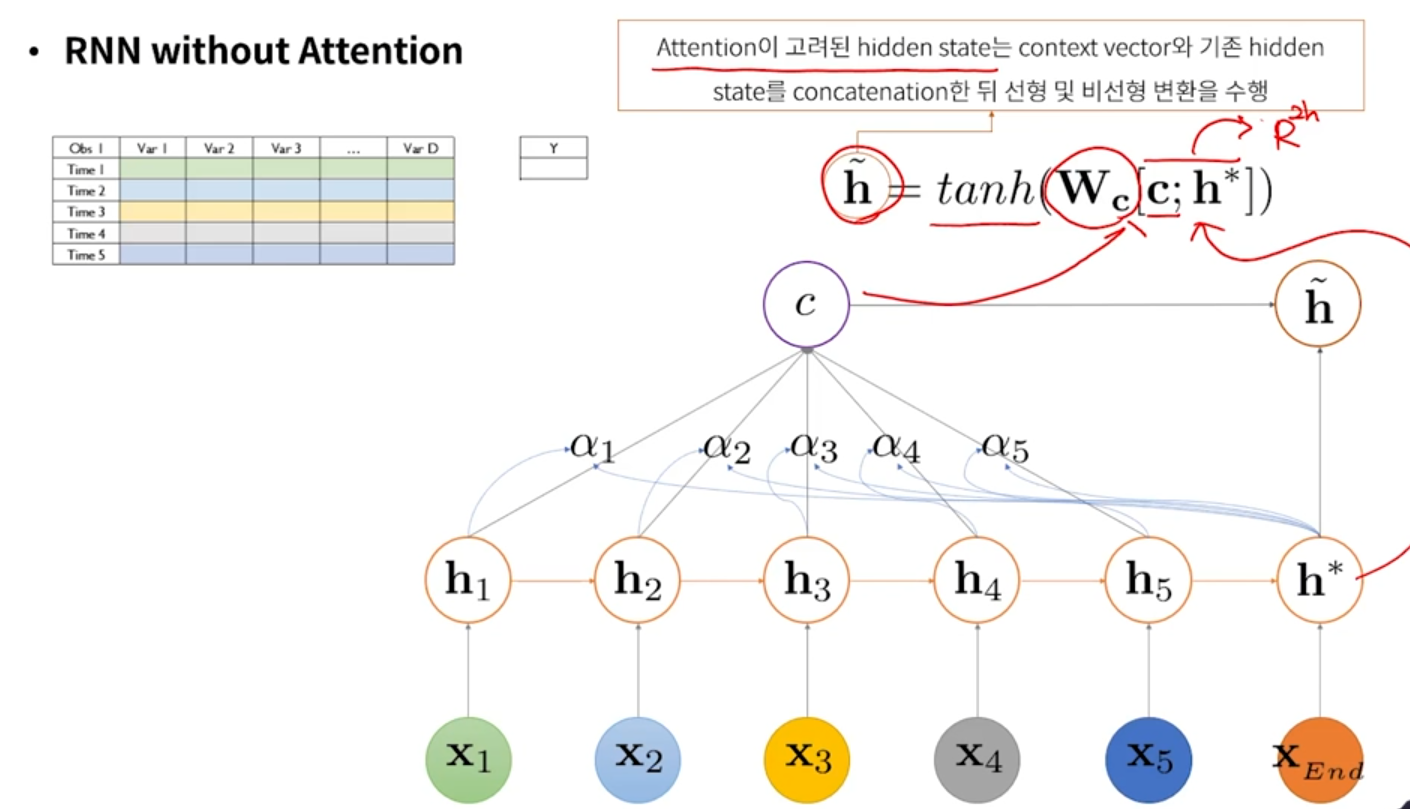
3. Attention이 고려된 hidden state
- h* : decoder 단에서의 hidden state가 지금 하나라고 가정한 것
4. output 계산
- 분류 문제일 경우 softmax 취함
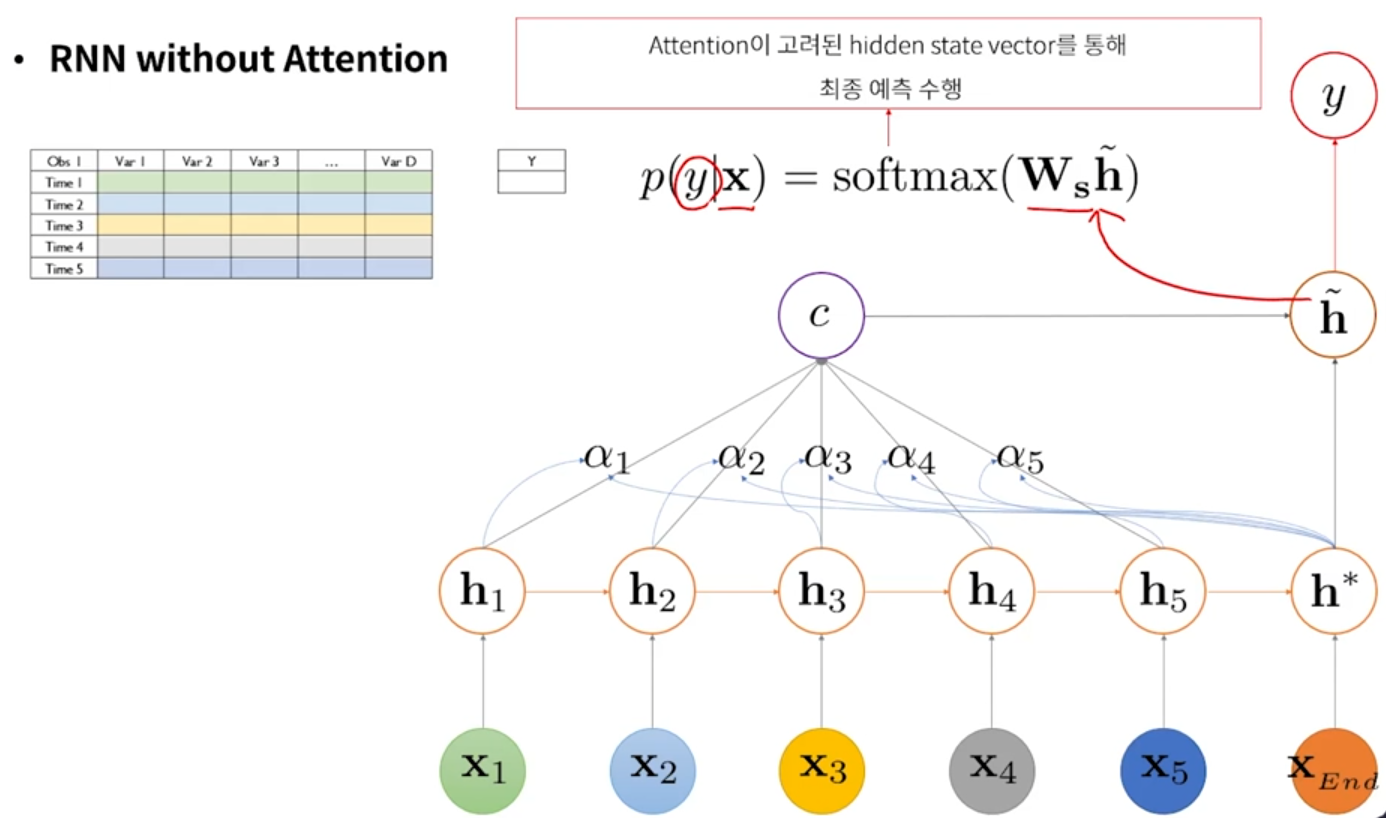
- Decoder의 단계마다, α 값이 다르게 산출된다.


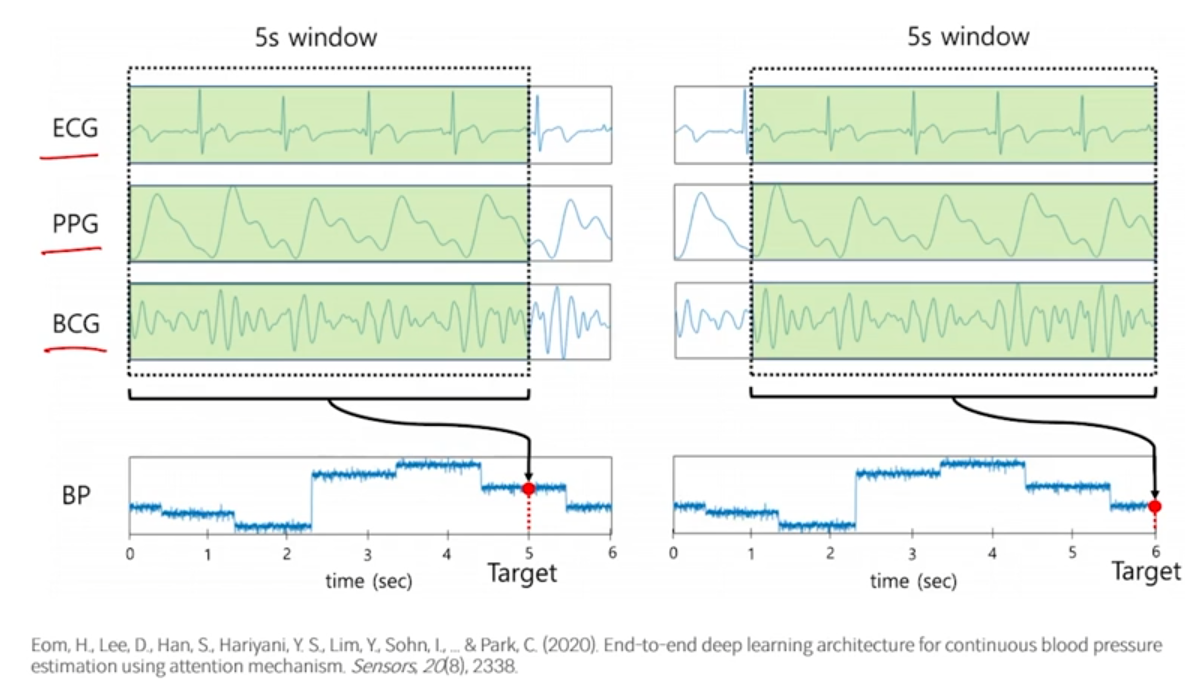
- 예시 : Blood pressure 예측
- 3개의 센서값을 이용(multivariate)해서 5초씩 window로 묶어서 예측한다.
- input data는 3개의 feature를 갖고 있는 것이고, 길이는 5초일 것
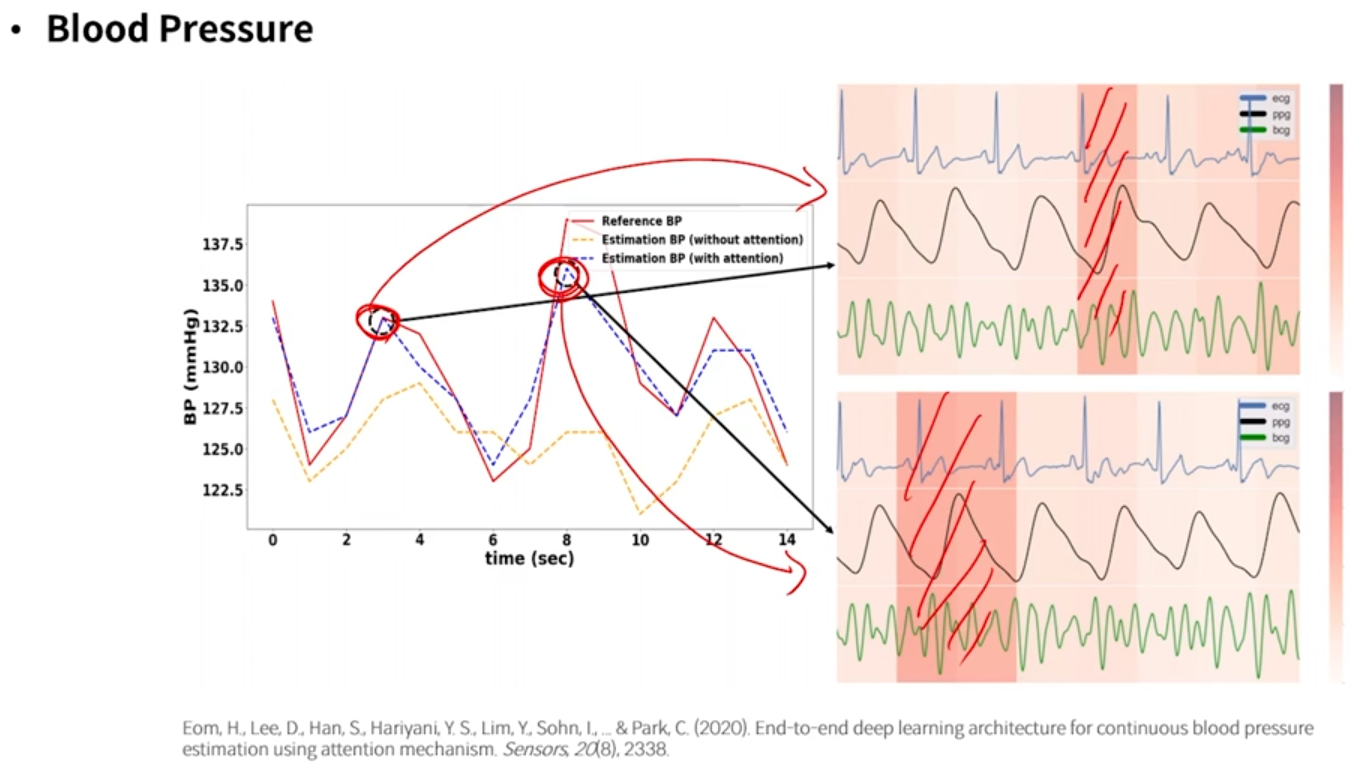
- blood pressure가 갑자기 높아졌을 때, attention score로 shading을 했을 때 영역이 다른 것을 볼 수 있다. 즉, 이러한 영역 안에서의 파동이나 패턴이 일반적인 상황과 어떻게 다른지 해석해볼 수 있는 것
'Deep Learning > 논문 리뷰' 카테고리의 다른 글
| RNN, LSTM (0) | 2021.01.13 |
|---|