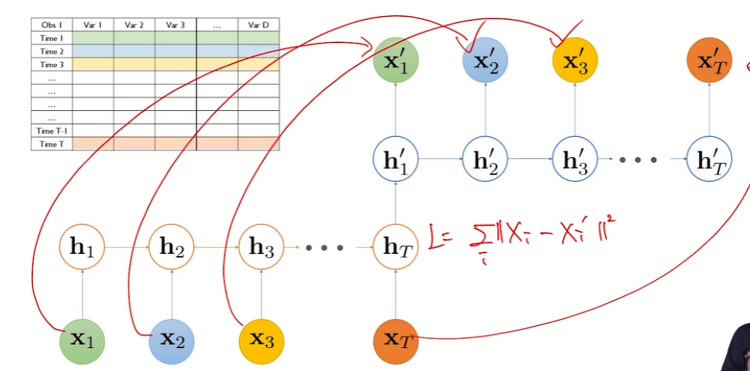
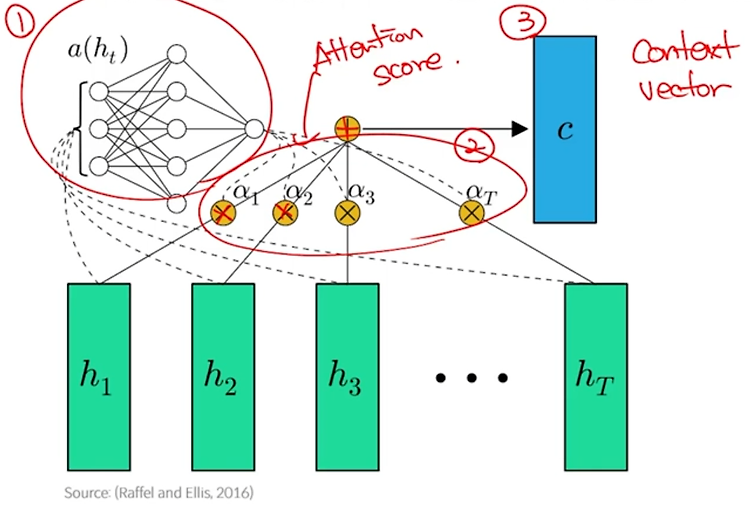
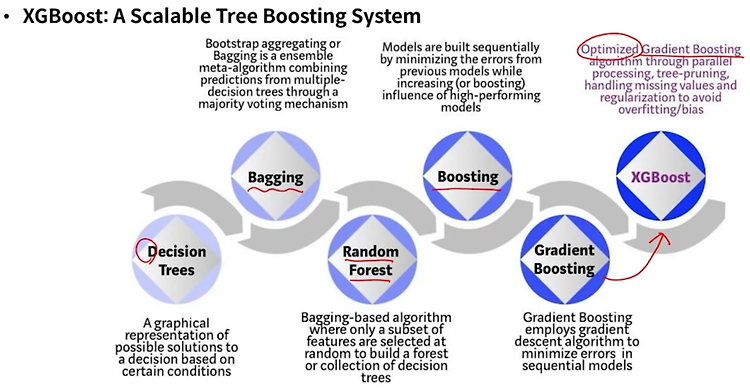
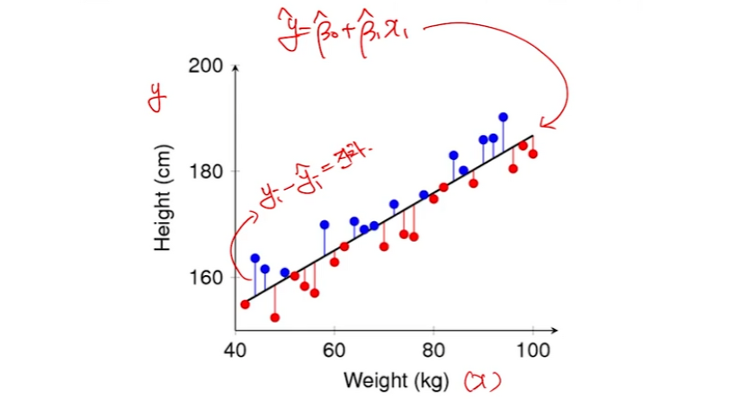
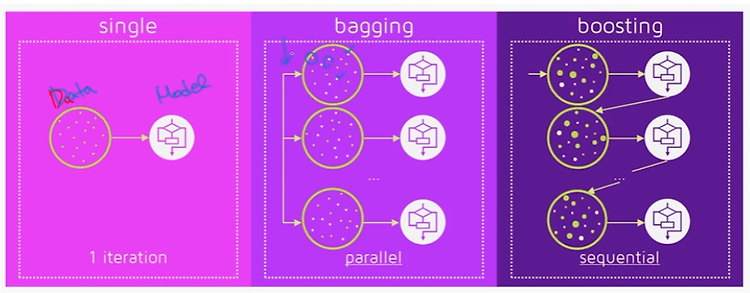
Ensemble model - 핵심 아이디어/효과, 배깅-부스팅 비교
앙상블의 목적 : 다수의 모델을 학습하여 오류의 감소를 추구 분산의 감소에 의한 오류 감소 : 배깅(Bagging), 배깅의 special case인 랜덤 포레스트(Random Forest) 편향의 감소에 의한 오류 감소 : 부스팅(Boosting) - Adaboost, GBM, XGboost, LightGBM, Catboost 등 분산과 편향의 동시 감소 : Mixture of Experts - 존재하기는 하나, 실제로 모델링할 때 control이 상당히 어려움 앙상블 구성의 두 가지 핵심 아이디어 다양성(diversity)을 어떻게 확보할 것인가? 최종 결과물을 어떻게 결합(combine, aggregate)할 것인가? 앙상블의 효과 앙상블의 다양성 Implicit : train data를 다르게 s..