- 고차원 데이터
- 변수의 수 많음 → 불필요한 변수 존재
- 시각적으로 표현하기 어려움
- 계산 복잡도 증가 → 모델링 비효율적
- 중요한 변수만을 선택 → 차원 축소
- 변수 선택 (selection) : 분석 목적에 부합하는 소수의 예측변수만을 선택
- 장점 : 선택한 변수 해석 용이
- 단점 : 변수간 상관관계 고려 어려움
- 변수 추출 (extraction) : 예측 변수의 변환을 통해 새로운 변수 추출
- 장점 : 변수간 상관관계 고려, 일반적으로 변수의 개수를 많이 줄일 수 있음
- 단점 : 추출된 변수의 해석이 어려움
- Supervised feature selection : Information gain, Stepwise regression, LASSO, Genetic algorithm, many more...
- Supervised feature extraction : Partial least squares (PLS)
- Unsupervised feature selection : PCA loading
- Unsupervised feature extraction : Principal component analysis (PCA), Wavelets transforms, Autoencoder
- PLS의 핵심
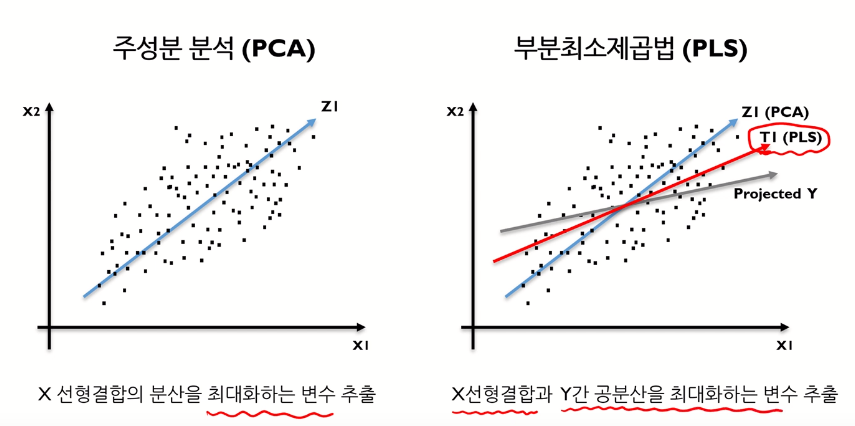
- PLS의 개요
- PLS는 Y와의 공분산이 높은 k개의 선형조합 변수를 추출하는 방식
- PLS (부분최소제곱) 용어는 선형조합으로 추출된 변수가 설명하지 못하는 부분에 (데이터 일부분) 지속적으로 최소제곱법을 사용하는 것에서 유래
- 주요 목적
∨ 회귀 및 분류 모델 구축
∨ 데이터 차원 축소 (n by p → n by k, where k <<p)
- 추출된 변수가 PCA에서는 반영하지 못했던 Y와의 상관관계를 반영하는 특징이 있으며
- 적은 수의 추출된 변수로 효율적인 모델 구축 가능
- PCA는 var(t)(=X 선형결합의 분산)만을 최대화하는 축(변수)을 찾지만, PLS는 이와 더불어 t와 Y의 상관관계를 최대화 하도록 축(변수)을 찾는다.

- PLS - 변수 추출 방법

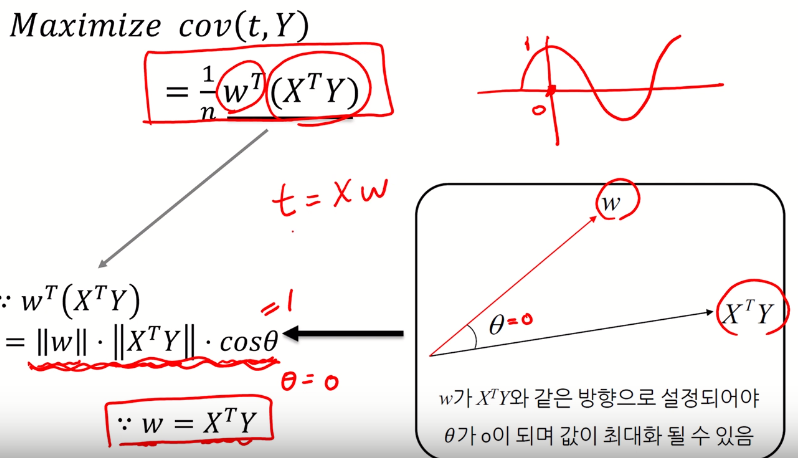
- PLS - NIPALS algorithm





- PLS - 예제







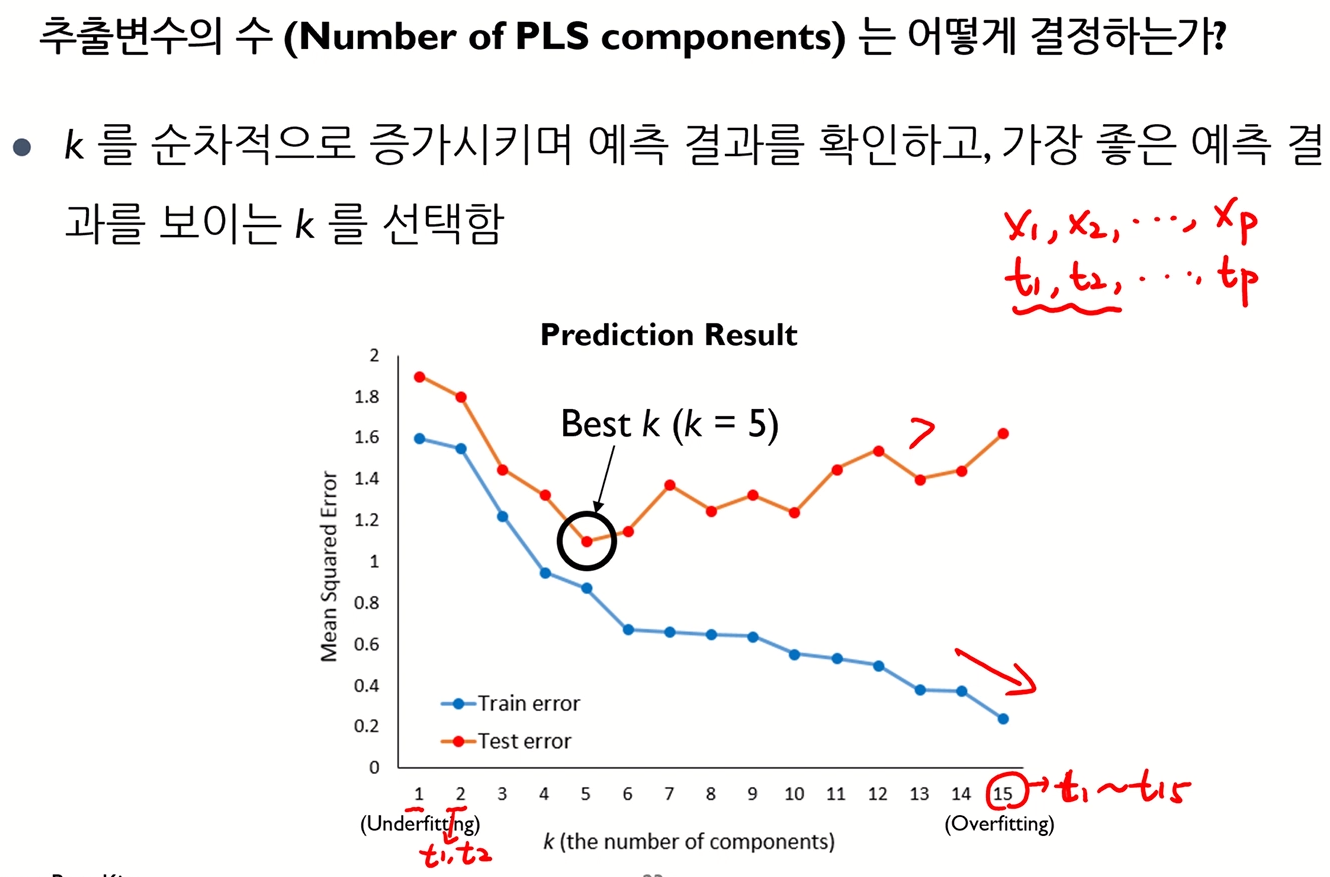
- PLS - 추출 변수의 수 결정
- PLS - 확장모델
1. 출력변수 Y가 여러 개일 때의 PLS → 하나의 PLS 모델로 여러 개의 Y 예측 가능
2. 출력변수 Y가 범주형일 때의 PLS (명칭 : PLS-DA (PLS-Discriminant Analysis))
- PLS - 출력변수 Y가 여러 개
- 출력변수 Y가 여러 개일 경우에는 기존의 방법대로 단 하나의 공분산 값을 추출할 수 없음
- 따라서 Y에서도 변수를 같이 추출하여, X와 Y에서 각각 추출된 변수들간의 공분산을 최대화 하도록 함




- PLS-DA (Discriminant Analysis)
- PLS-DA는 출력변수 Y가 범주형일 때 사용하는 방법으로, 출력변수를 처리하는 부분을 제외하면 기존 PLS와 동일함
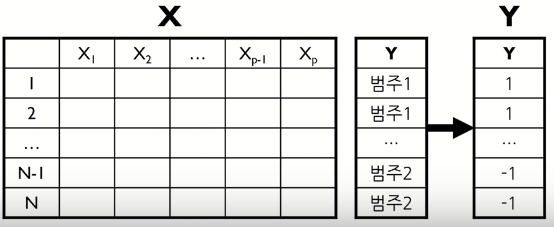
- 범주가 둘인 경우
∨ 첫 번째 범주를 1, 두 번째 범주를 -1로 설정하여, 기존 x와 새로 변환한 Y로 PLS를 사용
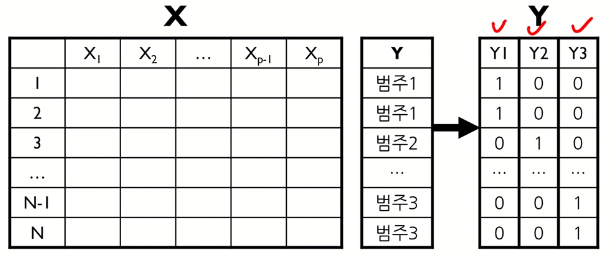
- 범주가 셋 이상인 경우
∨ 각 범주 별로 이진변수를 생성하여 특정 범주에 해당하면 1, 아니면 0으로 변환
∨ 기존 X와 변환된 Y를 이용하여 출력변수가 여러 개일 때의 PLS를 사용
[참조]
김성범 교수님의 https://www.youtube.com/watch?v=OCprdWfgBkc&t=1229s (PLS) 을 요약한 것입니다.
'Machine Learning > Algorithm' 카테고리의 다른 글
| Linear Regression (선형회귀모델) - 3 (파라미터 구간 추정, 가설 검정) (0) | 2020.02.10 |
|---|---|
| PCA reconstruction for anomaly detection (0) | 2020.02.06 |
| 다중공선성 존재할 때 선형 회귀 (0) | 2019.12.16 |
| Whitening transformation (0) | 2019.10.14 |
| Linear Regression (선형회귀모델) - 2 (파라미터 추정, 최소제곱법) (0) | 2019.10.13 |