- Microsoft 에서 개발 되었고, XGBoost 보다 나중에 제안된 모델
- Category 변수가 많은 데이터에 대해서 상당한 효과를 보는 알고리즘이다. 데이터의 특성을 잘 살펴서, 범주형 변수가 많을 경우 LightGBM을 우선순위로 염두에 두는 것도 좋다.

- 그래서 XGBoost에서도 모든 데이터를 스캔하지 않고, 부분부분으로 나누어서 스캔했었다.
- Gradient-based One-Side Sampling (GOSS)
- 상대적으로 gradient가 클 수록, 많이 틀렸다는 의미이니까 걔네들에 대한 정보를 많이 반영해야함
- graidnet가 작을수록 틀린 정도가 크지 않기 때문에 해당 데이터 포인트들은 다음 모델을 구축할 때 덜 중요하게 생각되어도 된다.
- 따라서, Large gradient를 가진 데이터는 keep하고, small gradient를 가지면 randomly drop하자.
- 즉, 스캔을 해야하는 데이터의 총량을 좀 줄이자!
- Exclusive Feature Bundling (EFB)
- 변수 길이를 줄이자
- 모든 변수에 대해서 모든 개체를 scan해서 split point를 찾아야 하니, GOSS는 관측치 수 줄이는거고, EFB는 변수의 수 줄이는거다.
- sparse한 변수는 좀 줄이자!
- GOSS


- 알파(a)와 베타(b) 하이퍼파라미터 사용한다.
- (1-a)/b = 1 보다 크도록 조절한다.
- a가 작을수록, b가 작을수록 실제 탐색하는 데이터의 수가 줄어들기 때문에 효율성은 증가하지만 정확도에 대해서 손실을 볼 수 있는 잠재적인 risk 가 있다.
- Top a * 100% 데이터는 모두 남겨놓는다.
- a=0.2, b=0.5, (1-a)/b=1.6>1
- Gradient 상위 20%는 split 포인트 찾는데에 모두 사용하겠다.
- Gradinet 하위 80%에 대해서는, 50%만 sampling 해서 얘네들만 사용해서 split 포인트 찾는데에 사용하겠다.
- EFB

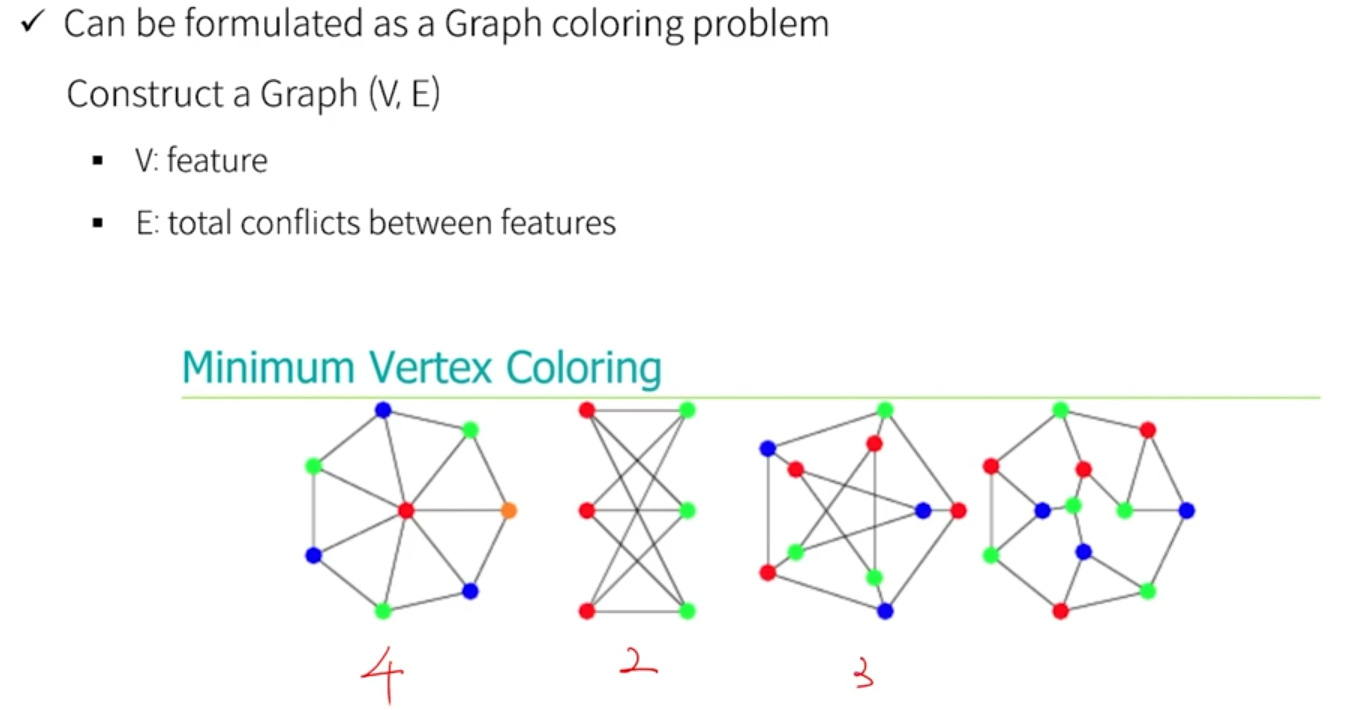
- 차례로, 4가지 색깔만 있으면 인접한 노드끼리 다른 색이면서 연결시킬 수 있다.
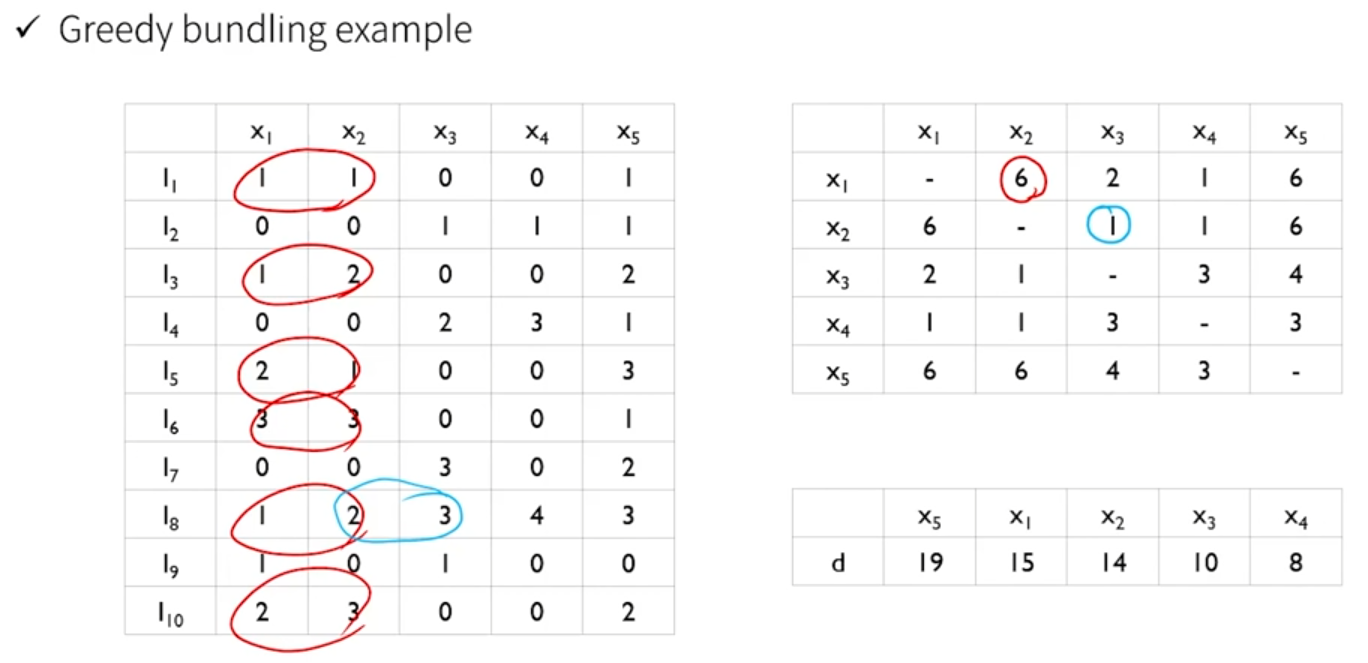
- 둘 다 0이 아니었던 데이터의 수를 계산한다.
- 그러고나서, 각 변수마다 그 값을 더해서, 각 변수의 conflict를 계산한다.
- 즉, conflict가 작다는 것은, 둘다 0이거나 하나의 값이 0인 데이터가 많다는 뜻이므로 묶을 수 있다.
- conflict가 크면 그 변수는 묶으면 안될 것이다.

- 그래프를 coloring을 하기 위해서 edge를 끊어내는 작업을 한다.
- cut-off=0.2 라면, 2번 이상 conflict가 있다면 잘라내는 것이다.
- 즉 conflict가 크면 묶지 말고 잘라내자.

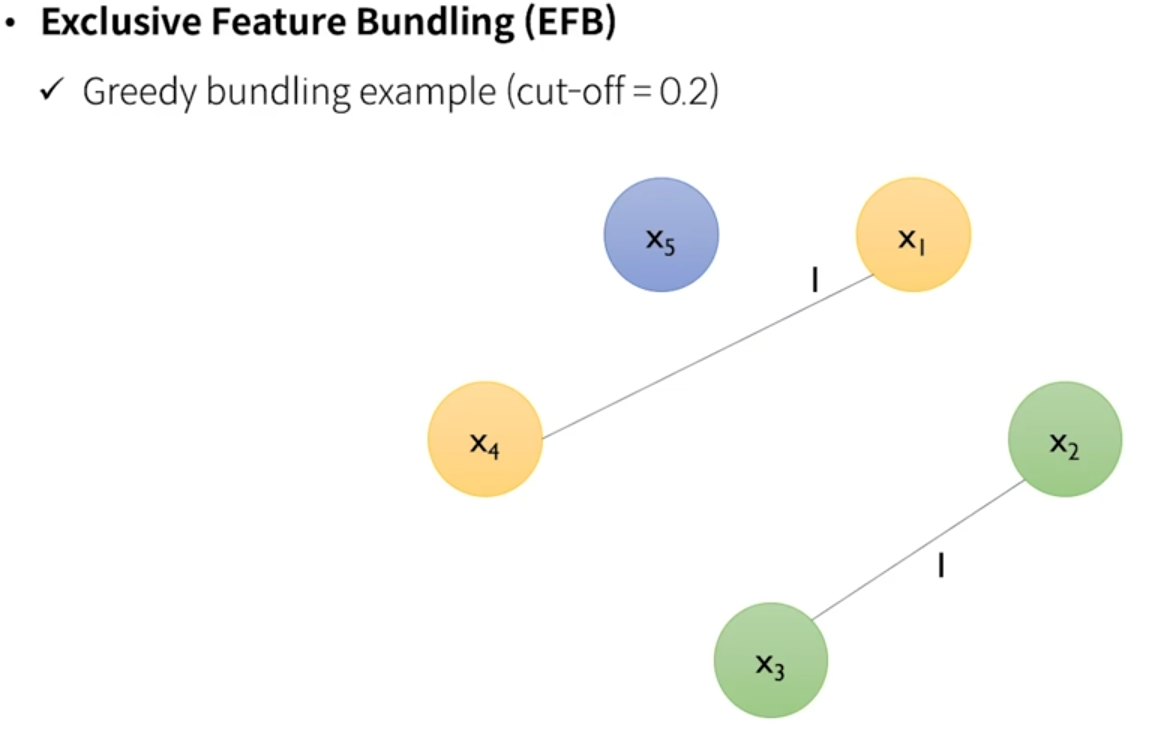
- 3개 색을 칠했기 때문에, 3개 변수로 bundling된 것
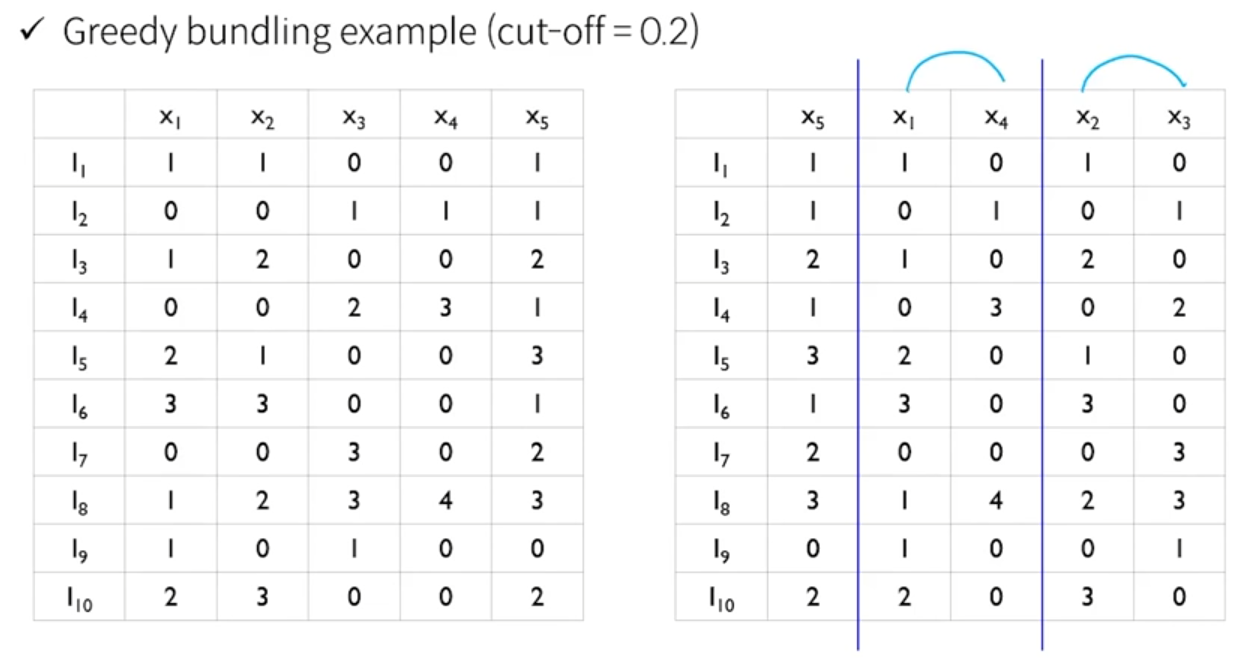
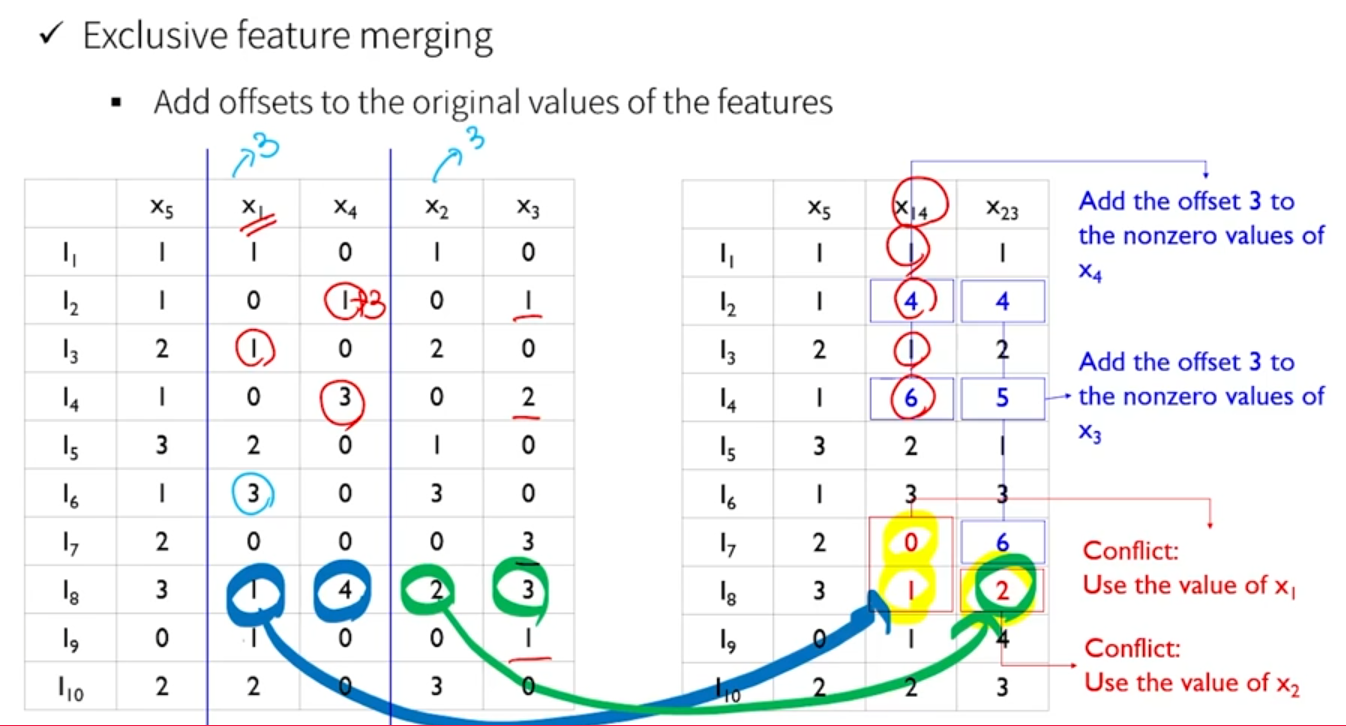
- 기준이 되는 변수가 가지고 있는 최대값을 두 번째 변수 값에 더해준다.
- 이렇게 하다보니, exclusive 하지 않는 경우(둘다 0이거나, 둘다 값 가지지 않는 경우)는 약간의 왜곡이 발생하기 때문에, 성능이 저하될 가능성도 있다. 실제적으로 해봤을 때는 상황에 따라 다르지만 category 데이터가 많을 경우 현실에서 작동 잘하는게 lightgbm이다.
- LightGBM 도 XGBoost 처럼 GBM의 대표적인 variant 중 하나이다.
- 데이터에 따라서 속도나 성능 비등비등하다.
- LightGBM을 더 효과적인 상황은 cagegorical 변수가 많아서 binding이 잘 될 수 있는 환경이다.
반응형
'Machine Learning > Algorithm' 카테고리의 다른 글
| Ensemble model - CatBoost (0) | 2022.07.22 |
|---|---|
| Ensemble model - XGBoost (0) | 2022.07.09 |
| Ensemble model - GBM (Gradient Boosting Machine) (0) | 2022.07.07 |
| Ensemble model - Adaboost (Adaptive Boosting) (0) | 2022.07.07 |
| Ensemble model - Bagging (0) | 2022.07.05 |