- Bagging : Bootstrap Aggregating
- 앙상블의 각 멤버(모델)는 서로 다른 학습 데이터셋을 이용
- 각 데이터셋은 복원 추출(sampling with replacement) 를 통해 원래 데이터의 수 만큼의 크기를 갖도록 샘플링
- 개별 데이터셋을 붓스트랩(bootstrap)이라 부름
- 이론적으로 한 개체가 하나의 붓스트랩에 한번도 선택되지 않을 확률

- 즉, 하나의 붓스트랩에 약 2/3 샘플이 선택되어 들어가 있음
- 선택되지 않은 샘플 : Out Of Bag (OOB)
- 개별 모델의 분산은 높고 편향이 낮은 알고리즘 (복잡도가 높은 알고리즘)에 적절함 (인공신경망, SVM(RBF, kernel width가 작은) 등) *****
- 배깅은 학습 데이터의 분포를 왜곡해서 noise를 주기 때문에, noise에 민감하게 반응하는 모델에 적용
- 복잡도가 높은 모델은 학습 데이터대로 과적합될 가능성이 높다. 그래서 bagging을 통해 학습 데이터 분포를 왜곡시키는 것이 효과가 좋다.
- 로지스틱 회귀를 가지고 배깅을 하는것은?
- 가능은 하지만, 크게 효과는 보지 못할 것이다.
- Bagging과 합이 잘 맞는 알고리즘 들은 모델의 복잡도가 높은 기법들이고, 그러한 기법들은 개별 모델의 분산이 높고 noise의 변화에 민감하게 반응하고 편향이 낮다.
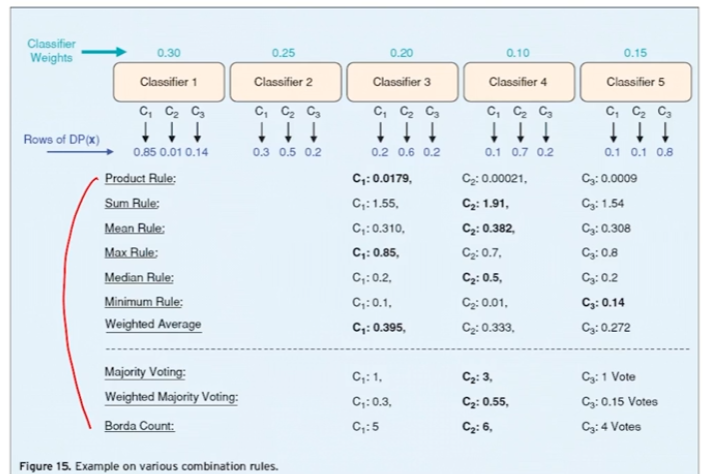
- Result Aggregating
- For classification problem
- Majority voting : 다수결의 원칙에 따라
- For classification problem
- Weighted voting (weight = validation accuracy of individual models)
- majority의 경우에는 4, 6은 0.4, 0.6의 확률이라고 할 수 있음
- 분모 : 전체 validation accuracy의 총합
- 분자 : 각 클래스의 validation accuracy 합
- 즉 P(y) 값은 안 쓴다.
- Weighted voting (weight = predicted probability for each class)
- validation accuracy, P(y=1) 동시에 고려해서 결과 aggregate 해도 된다.
- 논리적으로 설득이 가능하다면 가능한 것이다. survey paper를 봐도, 수십가지가 된다. 뭐가 좋다고 할 수 없고, majority voting부터 시작하되 조금 더 성능 향상을 취하고 싶을 때는 가중합 방식을 고려해보면 좋다.*****
- Result Aggregating
- Stacking
- 결과값을 다른 모델의 input으로 넣는 것
- bagging의 결과로 여러 붓스트랩마다 결과 나옴 → 그 결과들을 input으로 모델 생성
- 새로운 함수(모델)을 이용하여 aggregate 하는 것이다
- 실제로 많은 현실 문제에서 competition 같은 경우에도 현업의 데이터에서는 앙상블 기법이 매우 유용하게 쓰인다. 이 중에서 성능을 극한으로 끌어올리는 기술로서 stacking 사용된다.
- Stacking
- 알고리즘
- Bagging: Example
- 이래서 복잡도가 높은 모델과 합이 잘 맞는구나..!!
- 결과물 취합하는 방식은, logical 하다면 무엇이든 사용될 수 있다.
- Out of bag error (OOB error)
- 배깅을 사용할 경우, 학습/검증 집합을 사전에 나누지 않고 붓스트랩에 포함되지 않는 데이터들을 검증 집합으로 사용함
- 즉, train과 test만 나눠놓고, train data에서 OOB 데이터셋들로 검증할 수 있음
반응형
'Machine Learning > Algorithm' 카테고리의 다른 글
| Ensemble model - GBM (Gradient Boosting Machine) (0) | 2022.07.07 |
|---|---|
| Ensemble model - Adaboost (Adaptive Boosting) (0) | 2022.07.07 |
| Ensemble model - 핵심 아이디어/효과, 배깅-부스팅 비교 (0) | 2022.07.05 |
| Anomaly Detection - Extended Isolation Forest (0) | 2022.07.05 |
| Anomaly detection - AutoEncoder 활용 (1) | 2022.07.05 |