- 앙상블의 목적 : 다수의 모델을 학습하여 오류의 감소를 추구
- 분산의 감소에 의한 오류 감소 : 배깅(Bagging), 배깅의 special case인 랜덤 포레스트(Random Forest)
- 편향의 감소에 의한 오류 감소 : 부스팅(Boosting) - Adaboost, GBM, XGboost, LightGBM, Catboost 등
- 분산과 편향의 동시 감소 : Mixture of Experts - 존재하기는 하나, 실제로 모델링할 때 control이 상당히 어려움
- 앙상블 구성의 두 가지 핵심 아이디어
- 다양성(diversity)을 어떻게 확보할 것인가?
- 최종 결과물을 어떻게 결합(combine, aggregate)할 것인가?
- 앙상블의 효과

- 앙상블의 다양성
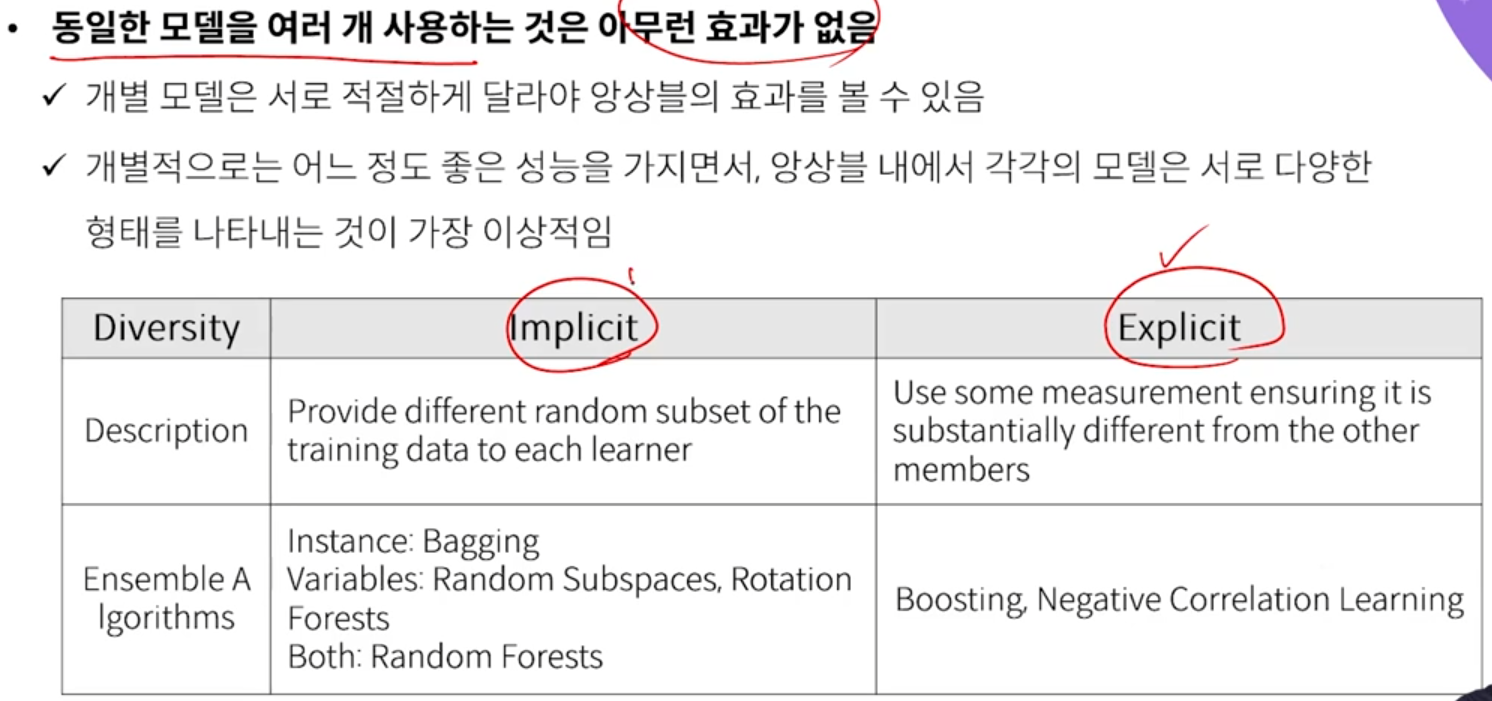
- Implicit : train data를 다르게 subset 구성하여 학습시키는 방식
- Explicit : 모델에게 이전 모델과는 다른 이런 것을 학습해야 한다. 라고 명시적으로 알려주는 방식

- Bagging이 병렬처리 가능해서 학습속도가 더 빠를 것 같지만 그렇지 않다.
- base learner가 계산 복잡도가 높은 Neural Net과 같은 무거운 모델인 경우가 많다. 하나 돌아가는데도 시간이 매우 걸린다.
- Boosting은 tree와 같은 단순한 모델 사용하기 때문에, 순차적으로 학습함에도 불구하고 학습시간이 더 빠르다.
반응형
'Machine Learning > Algorithm' 카테고리의 다른 글
| Ensemble model - Adaboost (Adaptive Boosting) (0) | 2022.07.07 |
|---|---|
| Ensemble model - Bagging (0) | 2022.07.05 |
| Anomaly Detection - Extended Isolation Forest (0) | 2022.07.05 |
| Anomaly detection - AutoEncoder 활용 (1) | 2022.07.05 |
| Anomaly detection - 밀도 기반 이상치 탐지 (Gauss, MoG, Parzen window) (0) | 2022.07.05 |